In our last blog post on kubernetes from scratch, we created a pseudo cluster to show how Kubernetes works inside. Today we are going to add a second node and make sure the cluster utilizes it.
Creating second node
What about having more than one node? What if we would like to schedule pods on 2 nodes? It is as simple as running kubelet on another node and making sure it connects to our API Server.
First of all, we assume that we have the first node from our previous blog post, with 10.135.53.41 internal IP, 46.101.177.76 external IP, running API Server, etcd and nginx deployment.
Now let’s create a second one, as before, replace --ssh-keys with your SSH key. After that, copy kubeletconfig file from the master node.
In the next step, you have to install essential prerequisites - Docker and Kubernetes node binaries. Install Dockerfollowing instructions from the previous part, and then install Kubernetes with:
In order to connect the kubelet with the API server, you have to set the kubeconfig.
Finally, you can run kubelet:
Now on k8s-master, we can check if the node has been recognized:
This is how our nodes look like now:
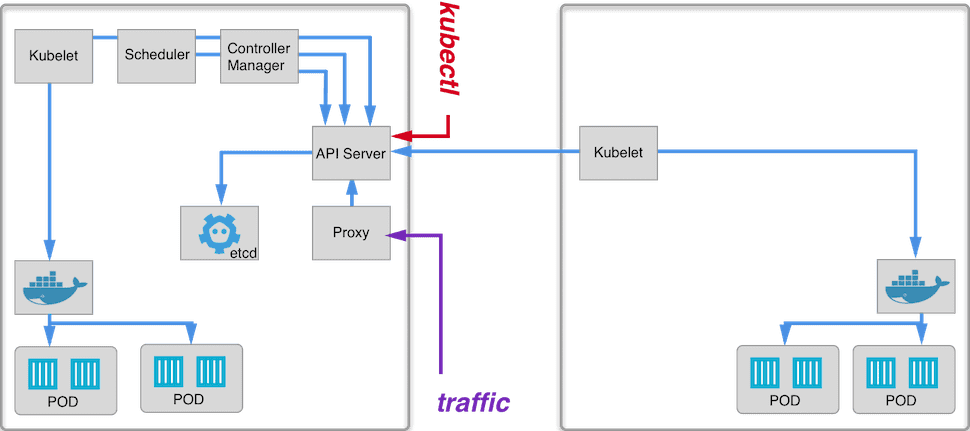
Next, let’s scale up our nginx deployment:
We can see that they are scheduled on both nodes.
Wait, can you see that pods have duplicated IP addresses? This is because we don’t have a way to manage IP address for pods among all nodes, this also means that there is no communication between pods located on different nodes.
To fix that we have to introduce another cluster component – network fabric.
Kubernetes networking using Flannel
Kubernetes makes specific assumptions about networking in the cluster:
- pods can communicate with each other by using unique pod’s IP address
- nodes can communicate with pods using unique pod’s IP address
- the IP that a container sees itself as is the same IP that others see it as
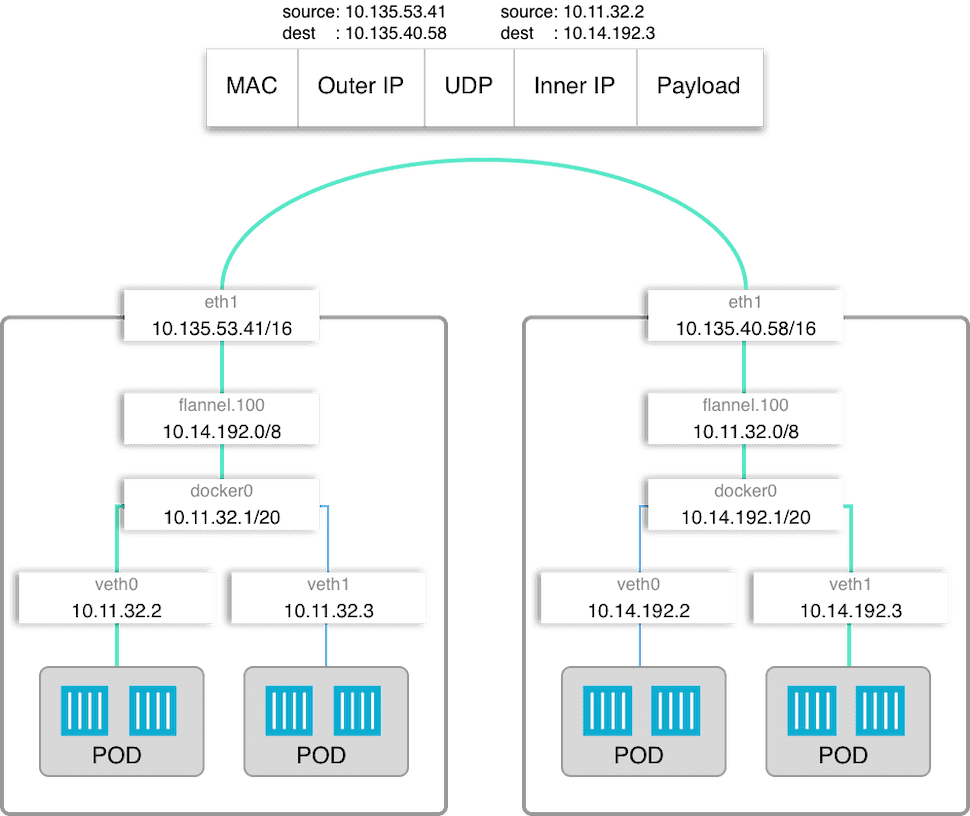
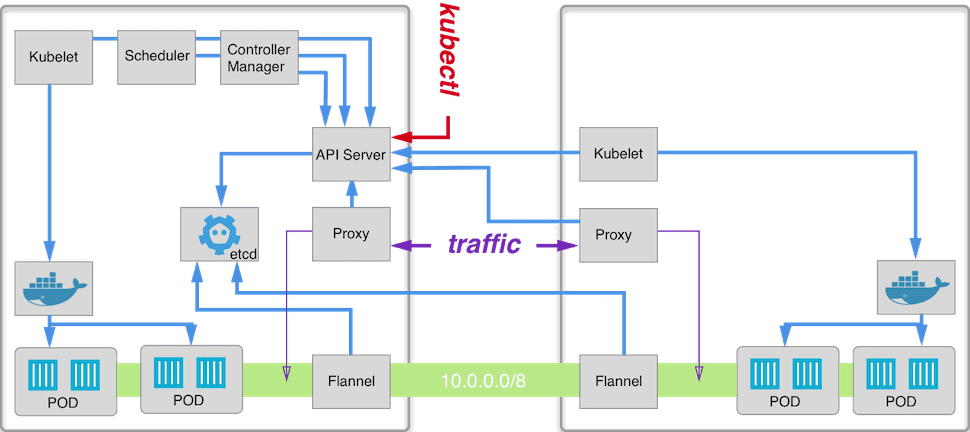
Kubernetes assumes that each pod and service in a cluster has a unique IP address and can communicate with other pods using their IP addresses. To achieve that we need a way to assign subnet of IP address for each node and ask Docker to use it when spawning containers, then we have to establish a non-NAT communication between these IP address. There is a lot of ways to do that, here we are going to focus on Flannel.
Flannel is one of the easiest ways to achieve these assumptions. Basically, Flannel runs as an agent on each node and is responsible for allocating a subnet for that node out of configured address space. That subnet is used by docker to obtain IP addresses for pods. Each subnet together with node’s IP address is stored in etcd and is readable by all agents. This allows flannel to obtain node location for given pod’s IP and forward traffic to that node.
This is how our networking will look like, it also shows how flannel works in the big picture.
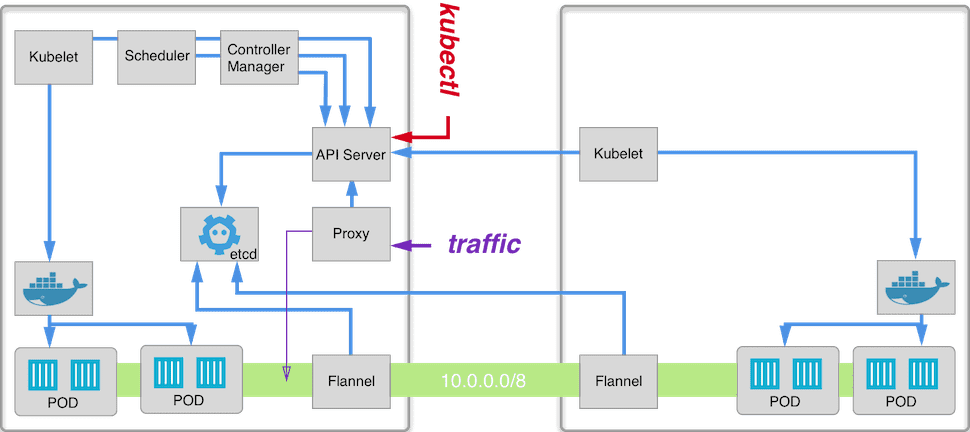
Applying what we’ve just learned, now we can run flannel on our nodes. The tricky part is to configure docker to use flannel. This is what we are going to do:
and now we can check pods’ IP addresses and try to ping them on different nodes:
Sweet, we have a pod to pod communication and this is how our nodes look like now:
Load balancing between nodes
So now we have both nodes fully capable of running pods, what about receiving traffic?
Currently, we accept traffic only on the first node, it will be forwarded to pods on the second node (by flannel) but this is not high availability solution – the first node is single a point of failure.
To solve that we should install Kube Proxy on all worker nodes, after doing that we can add an icing on our cake – DigitalOcean Load Balancer and balance ingress between nodes.
Everything works, we could even assume that we have production ready cluster 😀 but of course, we are far from that.
This is how our cluster looks now:
Setting up Kubernetes component - Ingress
Load balancer is a great tool to expose our cluster to the public, but still it's not the best what you can get.As your cluster will grow, possibly you'll end up in situation where you'll need more and more load balancers. Inproduction environment, usually you will want to replicate your control plane node for high availability, so youwill have to set up a load balancer balancing traffic between control plane nodes. Usually you will deploy a fewor lot of applications inside your cluster. That will lead you to setting up a load balancer of each application.The problem is, every load balancer costs money. Single load balancer does not cost a fortune, but as your kubernetes cluster grows, cost will become significant.You can solve this problem with another Kubernetes component - Ingress. Its task is to define routing rules to the services inside the cluster. For example, you can configure which service will be targeted depending on Host HTTP header.
First you will need an ingress controller which will be deployed as a NodePort service and previously createdload balancer will lead to it instead of nginx service. There is a variety of ingress controllers available, we will use NGINX controller here.
Running Flannel as a DaemonSet
When you were setting up the second node, probably you have noticed that there is a lot of repetitive work - running and configuring kube-proxy and flannel. As the cluster grows, likely there will be more services that will be needed on each node.For this purpose there are another Kubernetes resource - DaemonSet. DaemonSet does exactly that - it runs a pod on each node in the kubernetes cluster.
As you see, everything works as before, and now, if you add a node to the cluster, flannel will be set up automatically.You can now try setting up kube-proxy as DaemonSet yourself.
Wrapping up on Kubernetes deployment from scratch
In this blog post, we have learned how nodes in the kubernetes cluster communicate together and how pods are exposed to the outer world through services.Next we have learnt about two extremely useful Kubernetes resources - Ingresses and DaemonSets.There are more aspects of Kubernetes that we need to cover before we can say that our cluster is production ready. We are going to cover them in future blog posts, so stay tuned!
If you’d like to know more about our services for your business, don’t hesitate to get in touch.